Ghidra und MSVC WIN32 Programme
Für die Entwicklung von ausführbaren Programmen für Windows ist es üblich, Visual Studio zusammen mit zusammen mit dem MSVC Compiler und Linker zu verwenden. Visual Studio erledigt ein paar Dinge unter der Haube, um ein kleines C- oder C++-Programm in eine sichere und optimierte Anwendung zu verwandeln. Um dies zu verstehen, widmen wir uns einigen Dingen sowie WIN32 API-Besonderheiten, um diese erkennen können.
Aufrufkonventionen
Beim Aufruf einer Methode müssen die Argumente an die Methode übergeben werden. Die genauen Details dazu sind im Wikipedia X86-Aufrufkonventionen Artikel nachzulesen, aber die gebräuchlichsten, die man in einer Anwedungsdatei findet, sind:
cdecl
Dies wird üblicherweise von statischen Klassenmethoden verwendet (d.h. alles, was den Zustand der Instanz nicht verändert). Es wird auch von den meisten C-Methoden verwendet sowie sowie Methoden außerhalb einer Klasse.
stdcall
Der stdcall wird an den meisten Stellen der Windows-API verwendet, insbesondere bei Methoden, die aus DLLs importiert werden. Es kann schwierig sein, ihn von thiscall zu unterscheiden, nicht nur für einen selbst, sondern auch für Ghidra. Man erkennt sie am Register ECX und Stack als Eingabe und EAX als Ausgabe.
thiscall
Wie der Name schon sagt, wird er primär auf Klassen angewendet und in den meisten Fällen kann man von einem identischen Verhalten wie bei stdcall ausgehen. Ghidra kümmert sich um die Typverwaltung des this-Zeigers, was viel Arbeit erspart. Der this-Zeiger steht in ECX, die Argumente auf dem Stack und EAX ist die Ausgabe.
Importierte Funktionen ausfüllen
Ghidra kommt bereits mit einer langen Liste von Funktionsdefinitionen. Es deckt einen Großteil der der WIN32-API für verschiedene Versionen von Visual Studio ab. Die offizielle Liste ist unter ghidra-data auf github. Funktionen, die fehlen, aber importiert werden, können Sie einfach zu Ihrem Projekt hinzufügen. Eine gute Referenz ist der WINE-Quellcode der sie in bequemen und lesbaren Header-Dateien anbietet.
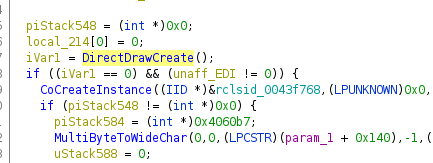
Ein gutes Beispiel ist DirectDrawCreate an. Beim Importieren einer
Anwendung, die darauf verweist, weiß Ghidra nichts über die Aufrufkonventionen
und Parameter, so dass man zwar den Namen, aber sonst nichts sehen kann:
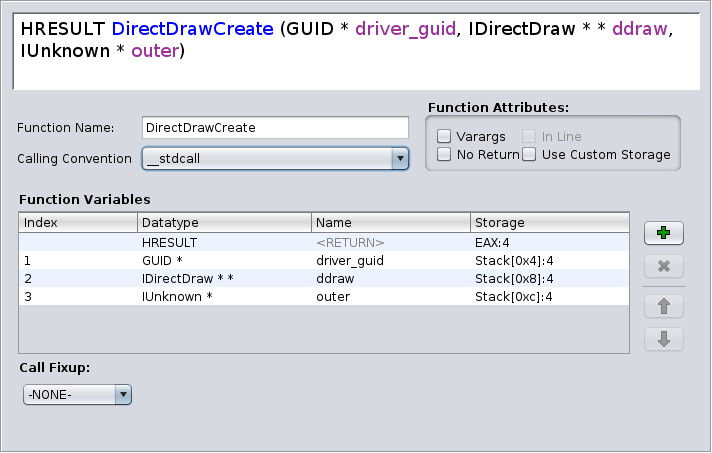
Im nächsten Schritt kann die Funktionsdefinition erstellt werden. Diese wurde aus wine’s ddraw.h entnommen.
Jetzt ist es möglich den Funktionsaufruf inkl. der Parameter und auch den entsprechenden Rückgabewert zu sehen. Dabei muss natürlich der Struktur und die Typ-Definition berücksichtigt werden. Während der Arbeit an diesem Beispiel habe ich eine Bibliothek mit den Typen für DirectDraw, Direct3D und Direct3D9 erstellt. Sie finden meine Typ Definitionen auf github.com/egore/ghidra-data.

Typisierung von GetProcAddress und LoadLibrary
Unter Windows können Funktionen aus einer Drittanbieter-DLL mittels LoadLibrary und GetProcAddress referenziert werden. Das folgende Beispiel zeigt das Laden und die sofortige Verwendung einer Methode einer DLL. Ohne Definition eines geeigneten Typs für die globalen DAT_XXXXXXXX-Felder, ist der Code kaum lesbar:

Allein die Umbenennung der Felder ermöglicht bereits eine bessere Erkennung. Kombiniert mit der Eingabe von den von Ghidra bereitgestellten Funktionsdefinitionen (z.B. “GetActiveWindow*” für GetActiveWindow), macht es den Code leicht lesbar. Man kann schnell sehen, dass dass dies MessageBoxA von user32.dll auf das aktive Fenster oder das letzte aktiven Popup.

Jeder, der mit der mit Durch die CRT hinzugefügte Magie vertraut ist, wird diese Funktion erkennen können diese Funktion: es ist der Fehlerpfad, wenn etwas vollständig schief gelaufen ist, um einen Fehlerdialog anzuzeigen, bevor das Programm beendet wird.
C++
Kompiliertes C++ bringt seine eigene Komplexität mit sich, vor allem was in Bezug auf dynamic_cast und virtuelle Methoden passiert. Eine wichtige Ergänzung ist der Ghidra-Cpp-Class-Analyzer, der tolle Arbeit bei der Identifizierung von Klassen und ihren virtuellen Funktionstabellen leistet. Es gibt aber einige händische erkennbare Muster, um Klassen zu identifizieren, die vom Plugin übersehen oder nur unvollständig erstellt wurden.
operator_new
In den meisten Fällen hilft die suche nach einer Methode namens operator_new suchen. Hinter den Kulissen ist es ein Wrapper um malloc (oder __nh_malloc und HeapAlloc wegen der CRT-Magie), und wird in den meisten Fällen von Ghidra erkannt. Sollte dies nicht der Fall sein (z.B. beim Reverse Engineering von Binärdateien aus dem letzten Jahrtausend) kann man es leicht selbst identifizieren. Einmal gefunden haben, wird man eine häufige Verwendung feststellen:

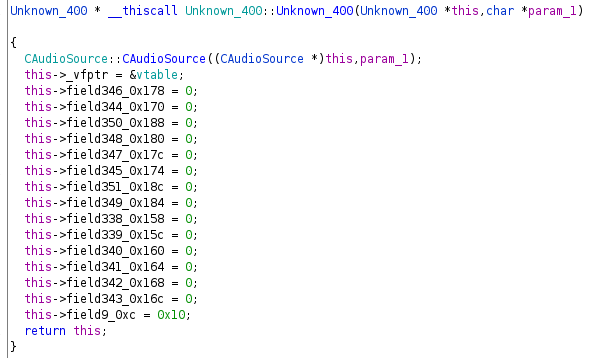
Im Beispiel sehen Sie eine Speicherzuweisung von 400 Bytes. Wenn diese Zuweisung erfolgreich durchgeführt wurde, wird sie sofort an eine Funktion übergeben, die sehr wahrscheinlich der Konstruktor ist. Da wir den Zweck dieser Klasse noch nicht kennen, habe ich sie “Unknown_400” genannt, um anzuzeigen, dass sie mir unbekannt ist, aber 400 Bytes hat. Außerdem habe ich die Methode umbenannt, damit sie wie ein Konstruktor aussieht.

Virtuelle Funktionstabellen (vtables, vftables, _vfptr)
Wenn Sie sich den Konstruktor genauer ansehen, werden Sie ein allgemeines Muster erkennen:
- Superklassenkonstruktoren werden aufgerufen (oder inlined, was häufig passiert)
- die Tabelle der virtuellen Funktionen wird eingerichtet
- die Felder der Klasse werden initialisiert
In unserem Unknown_400 Beispiel können wir genau das sehen, was oben beschrieben wurde.
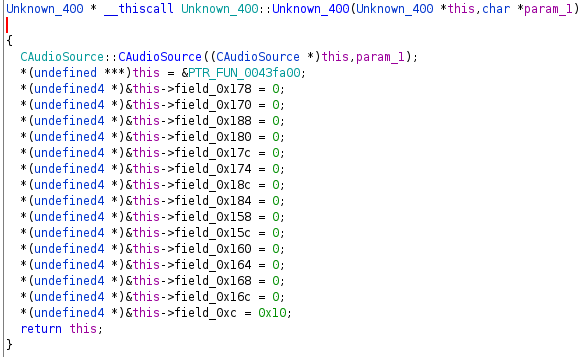
Dies verrät, dass PTR_FUN_0043fa00 wahrscheinlich eine Funktionstabelle ist: eine Liste
von Funktionen, von denen nur die erste von Ghidra ein Label erhalten hat (d.h.
weil sie per Adresse referenziert wird). Eine gängige Praxis ist die vtable
durch eine Liste von Zeigern zu ersetzen, welche von in Ghidras Decompiler verwendet wird,
und die Anzeige des Rückgabewerts sowie der Argumente nutzbar wird (die Einträge der Liste
sollten auf keinen Fall als undefined4 gar int, da der Decompiler sonst die Methoden
nicht richtig darstellt).

Durch die Verwendung von “Auto Fill in Class Structure” erhalten wir einen ziemlich anständig aussehenden Konstruktor:
Mit Hilfe des Verweises auf die vtable kann man auch den Destruktor finden, der häufig der erste Pointer der vtable ist. Der Destruktor wird das tun was der Konstruktor in umgekehrter Reihenfolge getan hat:
- die vtable zu unserer eigenen machen (für den Fall, dass sie von einer Kindklasse überschrieben wurde)
- Aufräumen der Felder
- den Destruktor der Superklasse aufrufen (oder ihn inlined haben)
IUnknown
Die Schnittstelle IUnknown wird in der WIN32-API verwendet, um eigene unbekannte Objekte zu verwenden,
bei denen nur die API bekannt ist. Sie unterscheidet sich von einer normalen
C++-Klassendefinition dadurch, dass man nichts über Mitgliedsvariablen Variablen wissen darf.
Betrachten wir das Beispiel von IDirectDrawColorControl aus WINE

Es erbt von IUnknown und bringt lediglich zwei Methoden mit. Um dies in Ghidra abzubilden, erstellen wir das notwendige Interface IDirectDrawColorControl sowie eine leere IDirectDrawColorControlVtbl, die von dem Interface referenziert wird.
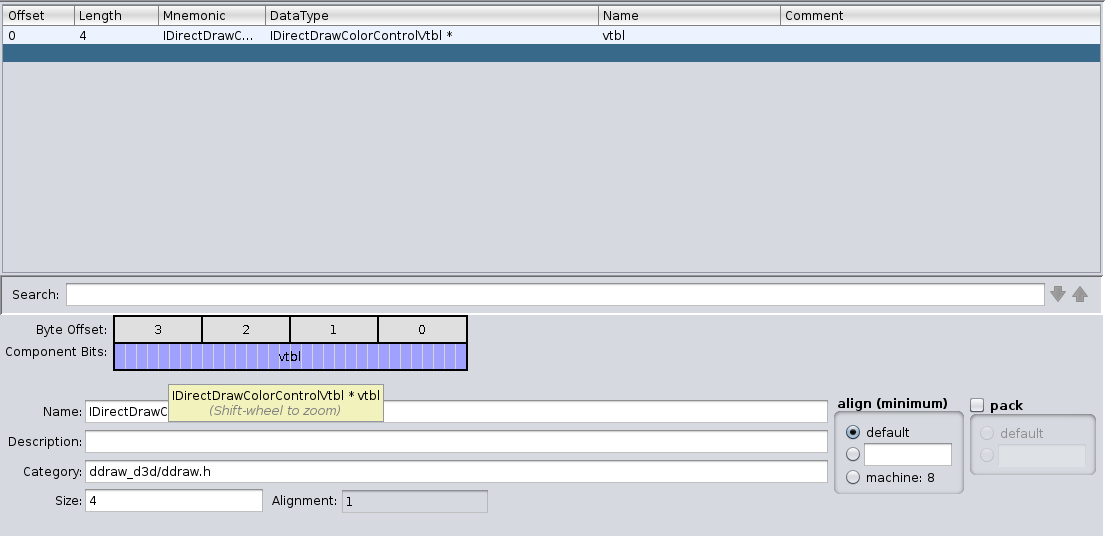
Um die vtable zu füllen, müssen die entsprechenden Funktions-Definitionen erstellen werden (wenn es für das Verständnis notwendig ist, ansonsten werden es nur Zeiger sein). Die ersten drei Methoden werden von IUnknown geerbt, so dass ich einfach die von Ghidra bereitgestellte IUnknownVtl wiederverwende.
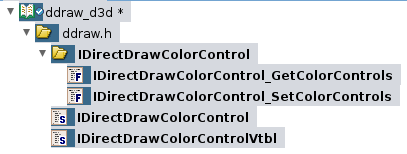

Das Hinzufügen der Funktionsdefinitionen ist in der Regel sehr zeitaufwändig. Es müssen zusätzliche Strukturen, Typedefs und Schnittstellen erstellen werden. Aber für komplexe Schnittstellen (z.B. IDirectDrawSurface vs. IDirectDrawSurface4 vs. IDirectDrawSurface7) wird eine korrekte Methodendefinition für das Verständnis schnell relevant.
Durch die CRT hinzugefügte Magie
Visual Studio wird dafür sorgen, dass Sie Programmierfehler vermeiden, indem es der C-Laufzeitumgebung (CRT) etwas Magie hinzufügt. Diese Magie ist nicht sichtbar im Code, sondern hinter den Kulissen. Am schnellsten sieht man es bei den dateibezogenen bezogenen APIs. Ich dachte, ich wüsste wie fopen funktioniert. Wenn man sich das Disassembly der dateibezogenen APIs anschaut, wird man etwas anderes feststellen: die FILE, die den Methoden übergeben wird, ist keine einfache Datei, sondern ein __crt_stdio_stream_data. Dies kombiniert ein FILE-Handle mit einem CRITICAL_SECTION zum Sperren von Dateizugriffen. Das ist in der Tat eine gute Idee mit einem akzeptablen Performance-Overhead (E/A ist eher der langsame Teil eines Aufrufs, nicht der Mutex) und es verhindert leicht Programmierfehler durch parallen Zugriff. Leider ist das Innenleben der Methoden notwednig, um diese zu erkennen. Ghidra 10.1 war noch nicht in der Lage, diese zu erkennen und kannte auch __crt_stdio_stream_data nicht.
Wie bereits angedeutet, verhalten sich einige Methoden ebenfalls anders. Zum Beispiel verwendet malloc intern
__nh_malloc, um Speicher mit Hilfe der Windows HeapAlloc APIs zu reservieren. Das ist zwar richtig,
bringt aber auch seinen eigenen Anteil an Komplexität in ein Binärprogramm.
Ausnahmebehandlung
Besonders in C++ muss man sich der Magie hinter den Kulissen der Ausnahmebehandlung bewusst sein. Unter Windows sind EH oder SEH (strukturierte Ausnahmebehandlung) vertreten, die in den Methoden für einige Unordnung sorgen.
Hinweise zur Ausnahmebehandlung](/posts/ghidra_win32/exception-handling.png)
Man kann in einer dekompilierten Methode in_FS_OFFSET, local_c, puStack8 und local_4 ignorieren, und sich auf den Positivfall konzentrieren, d.h. der Durchführung ohne dass das Programm Ausnahme auslöst. Das Thema Ausnahmebehandlung wird noch nicht durch den Ghidra-Decompiler unterstützt, um diese lesbar zu machen (siehe Ghidra issue tracker 2477).
/GS Puffer Sicherheitsüberprüfung
Wenn ein Programm mit der Compiler-Option /GS kompiliert wird, findet sich ein kleines bisschen Magie in jeder Methode, die den Stack benutzt (d.h. eigentlich überall). Man kann diese an ___security_init_cookie erkennen, die eine globale Variable einrichtet (gewöhnlich SECURITY_COOKIE genannt). In den Methoden gibt es dann einen zusätzlichen Prolog sehen:

Und Epilog:

Magie durch DLLs von Drittanbietern hinzugefügt
Manchmal kommt es vor, dass sich einige Codeteile sich ganz anders verhalten als andere. Das liegt in der Regel daran, dass sie von jemand anderem verfasst wurden, der andere Standards und Muster verwendet. So kommt es vor, dass manche Methoden die OutputDebugString protokollieren, während andere dies mit fprintf tun.
In manchen obskuren Codepfaden werden Sie über ein Verhalten stolpern, das schwer zu erklären ist. Ein wichtiger Aspekt ist, dass C und C++ auf Präprozessoren basieren. Damit sind verrückte Dinge möglich, wie z.B. einen eigenen Allokator zu schreiben und Folgendes damit zu tun
#undef new
#define new MY_WAY_BETTER_ALLOCATOR
Je nach Definition wird diese Definition nicht nur den eigenen Code verändern, sondern auch den von anderen.